Identificación dePerfiles de RiesgoCOVID-19
Analisis de 30M+ registros de la Secretaria de Salud de Mexico para identificar perfiles clinicos de riesgo mediante K-means y Fuzzy C-Means, con metricas comparativas, validacion interna y visualizaciones interactivas.
La pandemia generó datos masivos.
La pregunta es qué revelan.
México acumuló más de 30 millones de registros epidemiológicos entre 2020 y 2024. Este proyecto los analiza para identificar perfiles clínicos de riesgo mediante algoritmos de clustering no supervisado.
Triaje incierto
Sin perfiles claros de riesgo, la priorización clínica se basa en criterios aislados, no en patrones multivariados reales.
30M+ registros sin explotar
Datos masivos de la Secretaría de Salud con potencial analítico enorme, pero sin segmentación sistemática.
Complejidad multivariada
Comorbilidades, edad, sexo y variables clínicas interactúan de formas no lineales que requieren clustering no supervisado.
Linea temporal del registro
Inicio de la pandemia en México
Primeros registros masivos de casos y defunciones, sobrecarga hospitalaria.
Picos de mortalidad y variantes
Segunda y tercera ola, saturación de UCIs, datos epidemiológicos crecientes.
Estabilización progresiva
Vacunación masiva, descenso de casos graves, normalización gradual.
Registro y análisis retrospectivo
30M+ registros acumulados disponibles para análisis de perfiles de riesgo.
Pipeline reproducible,
de datos crudos a perfiles clínicos.
Seis etapas estructuradas en Jupyter Notebooks, desde la ingesta de datos hasta la comparación de algoritmos. Cada paso es trazable y reproducible.
Carga de datos
Descarga automatizada desde la DGE y carga de 30M+ registros en DataFrames optimizados.
00_carga_datos.ipynbExploracion
Analisis temporal, distribuciones demograficas, completitud de registros, valores faltantes y outliers.
01_exploracion_datos.ipynbPreprocesamiento
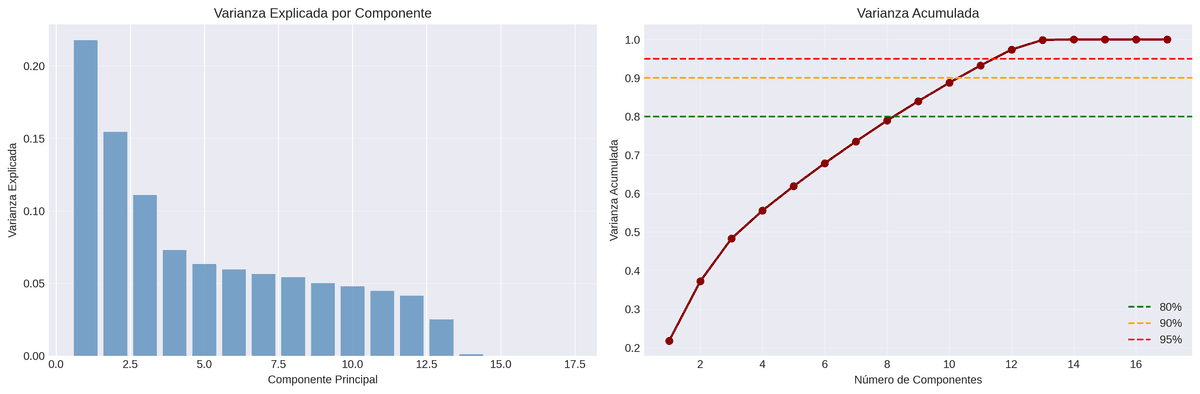
Muestreo estratificado (5%), one-hot encoding, estandarizacion, PCA para visualizacion, analisis VIF.
02_preprocesamiento_limpio.ipynbK-Means Clustering
Metodo del codo, analisis de silueta, seleccion de k=9 clusters, perfilamiento e interpretacion clinica.
03_kmeans_analisis.ipynbFuzzy C-Means
FPC para seleccion de c=2, membresias parciales, analisis de ambiguedad, comparacion con K-Means.
04_fuzzy_cmeans_analisis.ipynbComparacion y validacion
Matriz de confusion, Adjusted Rand Index, concordancia, analisis de puntos discordantes.
05_comparacion_resultados.ipynb17 Variables de entrada
Estrategia de muestreo
Flujo del pipeline
Nueve perfiles clínicos revelan
la estructura oculta del riesgo.
K-Means identificó 9 clusters con perfiles diferenciados de riesgo, desde jóvenes sin comorbilidades hasta adultos mayores con 4+ condiciones crónicas.
Los algoritmos clasifican a la mayoria de pacientes en grupos diferentes — capturan estructuras complementarias.
Concordancia baja: K-Means y Fuzzy C-Means revelan patrones distintos del mismo dataset.
Cluster K7 presenta la mayor carga de comorbilidades: diabetes, hipertension, obesidad, cardiovascular.
El cluster mas critico: todos los pacientes intubados, edad promedio 66.7 anos.
Perfiles K-Means — Clusters principales
| Cluster | n | % | Edad μ | Hosp. | Intub. | Comor. μ | Perfil | Riesgo |
|---|---|---|---|---|---|---|---|---|
| K1 | 11,387 | 19.5% | 75.8 | 97.8% | 0% | 0.70 | Adultos mayores fragiles, hospitalizados con pocas comorbilidades registradas | ALTO |
| K7 | 4,591 | 7.8% | 68.6 | 96.6% | 5.8% | 4.05 | Mayor carga de comorbilidades del estudio: 4+ condiciones promedio | CRITICO |
| K3 | 6,050 | 10.3% | 66.7 | 100% | 100% | 1.81 | 100% intubados — casos criticos en UCI, alta severidad | CRITICO |
| K4 | 3,044 | 5.2% | 33.4 | 100% | 100% | 0.52 | Jovenes intubados sin comorbilidades — severidad inesperada | ALTO |
| K6 | 10,044 | 17.2% | 37.3 | 81.6% | 0% | 0.47 | Jovenes hospitalizados con minimas comorbilidades | MODERADO |
| K5 | 4,401 | 7.5% | 54.9 | 47.7% | 1.2% | 3.33 | Pacientes con multiples comorbilidades, hospitalizacion parcial | ALTO |
Comparacion de metricas
Comparacion PCA 2D
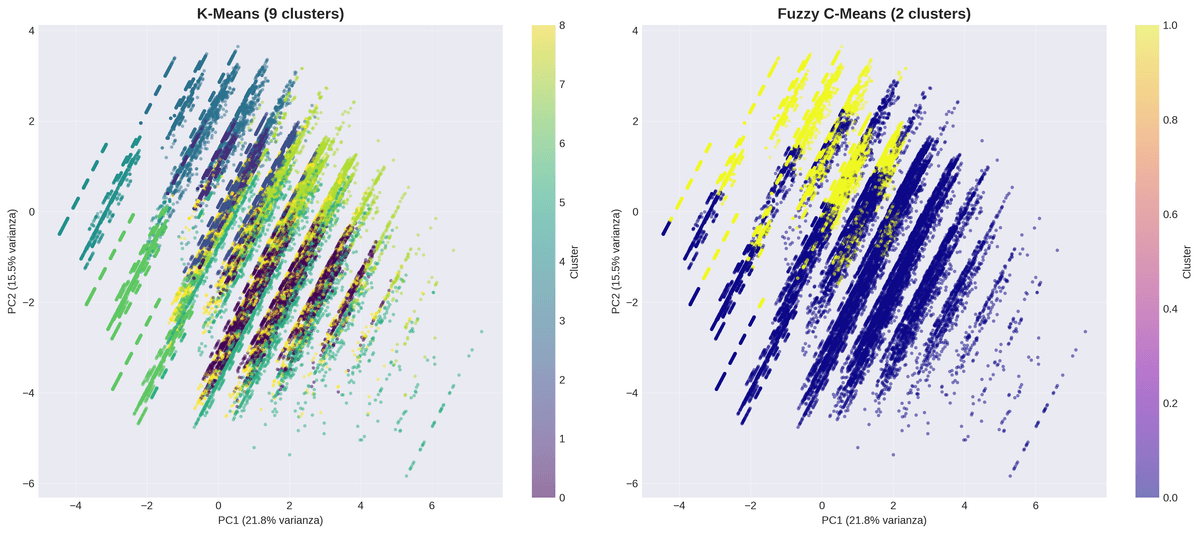
Hallazgo clave: Ambigüedad total en Fuzzy C-Means
Los 58,497 pacientes obtuvieron membresía exacta de 0.50 en ambos clusters fuzzy — ningún punto fue clasificado con certeza. Esto indica que con c=2, el algoritmo no pudo discriminar subgrupos claros, sugiriendo que la estructura natural del dataset requiere más clusters o un preprocesamiento diferente.
46 figuras generadas,
cada grafica cuenta una historia.
Galeria completa de las visualizaciones producidas en el analisis: distribuciones, heatmaps, PCA, metricas de clustering y analisis epidemiologico.
Lo que los datos revelan
y lo que queda por descubrir.
K-Means produce clusters clinicamente interpretables
9 clusters con perfiles diferenciados: desde jovenes sin comorbilidades (K6) hasta adultos mayores con 4+ condiciones cronicas (K7). Cada cluster tiene implicaciones directas para triaje y asignacion de recursos.
Fuzzy C-Means revela ambigüedad inherente
Con c=2, todos los pacientes obtuvieron membresía de 0.50 — ambigüedad total. Esto no invalida el método, sino que evidencia que la frontera entre perfiles de riesgo no es binaria.
Los algoritmos capturan estructuras complementarias
72.6% de discordancia y ARI de 0.107 confirman que K-Means y Fuzzy C-Means no son redundantes: ofrecen perspectivas complementarias del mismo fenómeno epidemiológico.
El riesgo no depende de una sola variable
La combinación edad + comorbilidades + tipo de atención define perfiles de riesgo más informativos que cualquier variable aislada. El análisis multivariado supera los enfoques univariados.
Limitación crítica: variable de resultado
100% de mortalidad en todos los clusters indica un problema de calidad en la variable FALLECIDO, no corregido en el pipeline. Lección: validar variables de resultado tempranamente.
Trabajo futuro
- Probar HDBSCAN y Gaussian Mixture Models para comparación más completa
- Incluir datos de vacunación y variantes genómicas si disponibles
- Reducir a 4–5 clusters K-Means para comunicación clínica más directa
- Implementar validación externa con datos clínicos reales
- Desarrollar herramienta interactiva de clasificación de riesgo en tiempo real